Iceberg Tables
- Snowflake supports:
- parquet files
- hidden partitioning: unlike hadoop, supports partitioning on column expression, the computed partitioning column is hidden
- cross-platform/region external volumes: for Snowflake managed iceberg tables, Snowflake will bill data transfer fees
- V1 and V2 supported, except:
- Row-level deletes
history.expire.min-snapshots-to-keep table property- tables with partition spec that refer identity or if the source column doesn't exist in the parquet file
- data type
unsigned int
- temporary/transient tables, cloning, replication, sharing
- clustering tables defined using catalog integration
- V2 format offers copy-on-write or merge-on-read strategies for updates and deletes
- copy-on-write: rewrites affected files. It is best suited for frequent reads, large but infrequent updates
- merge-on-read: (currently unsupported) maintains a delete file, and no rewrites. It is best suited for frequent writes/updates
Storage
- Uses external volume
base_location_prefix can be set at account/database/schema levels- file names:
storage_base_url/<table-path>/[data | metadata]/
base_location |
base_location_prefix |
table-path |
|
|
|
Yes | * | `base_location.randomId`
- | Yes | `base_location_prefix/<table>.randomId`
- | - | `<database>/<schema>/<table_name>.randomId`
Catalog
- Catalog can be managed by Snowflake or externally (e.g. AWS Glue) using Catalog Integration
- For unmanaged Iceberg tables,
DATA_RETENTION_TIME_IN_DAYS is set to smaller of history.expire.max-snapshot-age-ms or 1 for standard edition or 5 for enterprise edition
Catalog Integration
- for creating iceberg tables that are managed externally. Following types using
catalog_source (required)
- AWS Glue (
glue)
- Object Storage (
object_storage)
- Snowflake Open Catalog (
polaris)
- Iceberg REST (
iceberg_rest)
- SAP Business Data Cloud (
sap_bdc)
table_format is always iceberg, except for catalogs using object storage which also supports deltacreate catalog integration .... Options:
Catalog Linked Database CLD
- A database that is linked to a catalog integration, and optionally an external volume if catalog integration does not support vended credentials
- nested namespaces can be ignored or flattened
- A task runs every 5 minutes to discover newly added schemas and tables.
- does not yet support dropped or renamed schemas/tables
- All discovered schemas and tables are owned by the same role that owns CLD
- For write-enabled CLD, dropping a table is committed to the catalog and thus is also dropped in ICEBERG catalog
- Support can use
SYSTEM$UNLINK_TABLE to remove table from CLD but not drop in ICEBERG catalog
- Use
SYSTEM$CATALOG_LINK_STATUS to check for any failing sync
Architecture
- Architecture compared to Hive, which is directory based (i.e. all files in a directory, which is also a partition), Iceberg's metadata contains list of files. This allows
- better performance on cloud storage by tracking individual files instead of directories
- files can have different prefixes
- costly directory listings are avoided
- transactional abilities, directories are managed by filesystem and aren't transactional
- time-travel (iceberg supports snapshots)
- can support compaction via background process
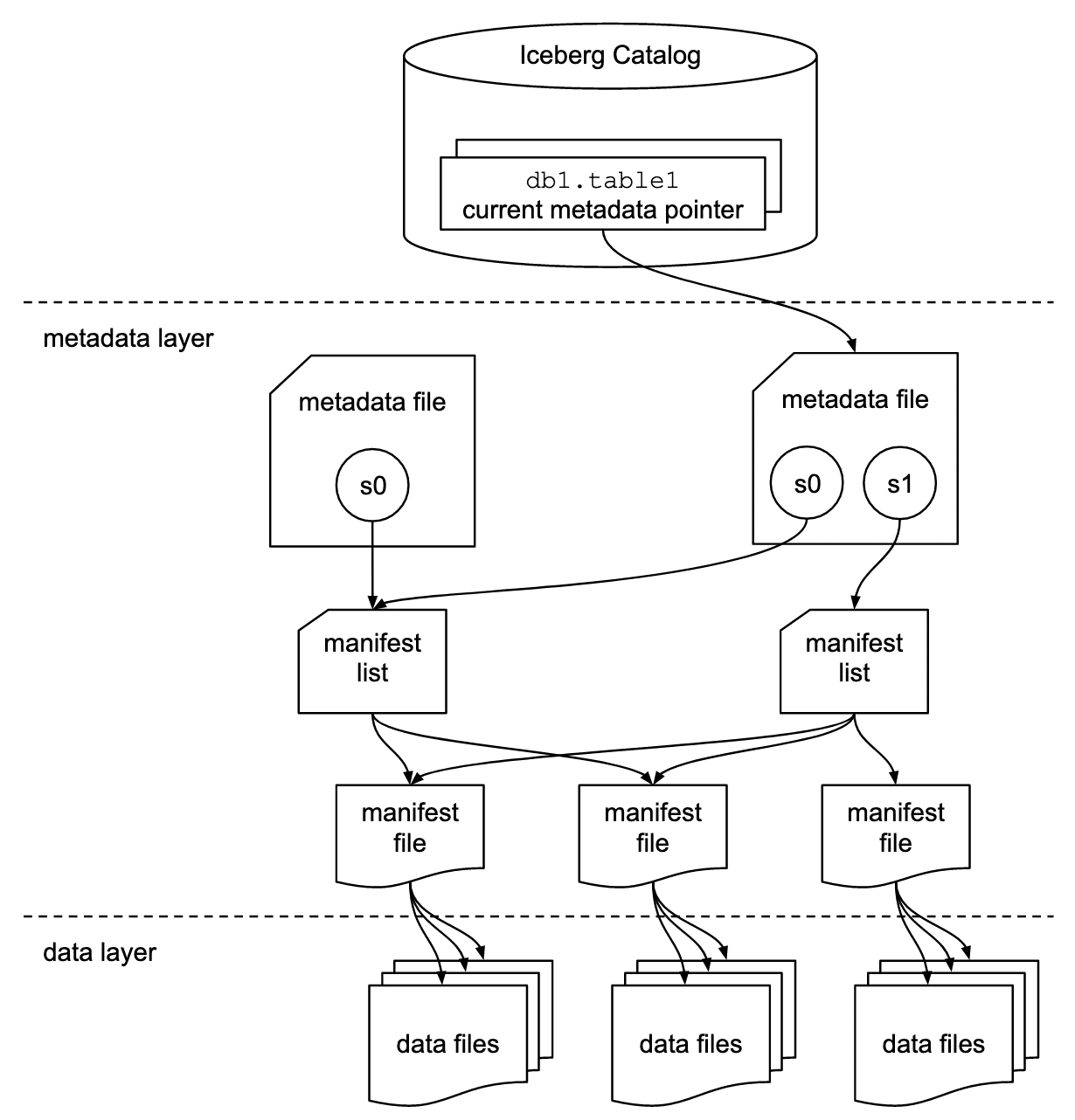
- Iceberg table consists of 3 layers
- catalog: contains table and its current metadata-file
- metadata:
- metadata-file: contains schema, partition information, list of snapshots (manifest list), and which snapshot is current
- manifest list: A list of all manifest files that make up a snapshot
- manifest file: tacks a subset of data files along with details (file type such as parquet) and statistics (such as row count, null counts, values, min, max etc)
- data: typically parquet files
{kind=link}